手把手教你用 FastAPI + Qwen 实现流式 AI 聊天:前端实时响应,后端一行不卡
🌟手把手教你用 FastAPI + Qwen 实现流式 AI 聊天:前端实时响应,后端一行不卡!
关键词:FastAPI、Qwen、流式响应、SSE、OpenAI 兼容 API、前端实时聊天
你是否也曾想过,自己动手搭建一个像 ChatGPT 那样“边打字边出结果”的 AI 聊天界面?
其实,借助 FastAPI + 阿里通义千问(Qwen) 的流式接口,配合简单的前端 HTML,你完全可以在 100 行代码内实现一个高性能、低延迟的流式对话系统!
今天,我们就从零开始,一步步带你搭建一个支持 实时流式输出 的 AI 聊天应用。
🚀 为什么选择流式响应?
传统的 AI 接口往往是“等全部生成完再返回”,用户要盯着空白屏幕几秒钟,体验很差。
而流式响应(Streaming Response) 则像真人打字一样,AI 一边思考一边输出,用户立刻看到反馈,交互感拉满!
技术上,我们使用 SSE(Server-Sent Events) 协议,让后端持续向前端推送数据,无需轮询、无需 WebSocket,简单又高效。
🛠️ 技术栈一览
- 后端:FastAPI(Python)
- AI 模型:阿里云 DashScope 的
qwen-plus(兼容 OpenAI API) - 前端:原生 HTML + JavaScript(无框架,轻量易懂)
- 部署:本地开发即可运行(支持 Docker 扩展)
💡 本文代码已在 Python 3.12 环境下测试通过,依赖
fastapi、openai、python-dotenv、uvicorn。
🔐 第一步:配置 API 密钥
首先,在项目根目录创建 .env 文件:
1 | DASH_SCOPE_API_KEY=你的阿里云 DashScope API Key |
你可以在 阿里云 DashScope 控制台 免费获取 API Key,并启用
qwen-plus模型。
🐍 第二步:FastAPI 后端代码(main.py)
1 | # main.py |
✅ 关键点解析:
- 使用
StreamingResponse返回 SSE 流。 - 调用 DashScope 的 OpenAI 兼容模式,只需改
base_url。 - 每个
chunk通过yield实时推送,前端逐字渲染。
💬 第三步:前端页面(index.html)
前端非常简洁,仅用原生 JS 处理 SSE 流:
- 用户输入问题 → 发送 POST 请求
- 收到流式响应 → 逐字拼接显示
- 自动滚动、打字动画、错误提示一应俱全
👉 完整 HTML 代码较长,这里不贴全文(文末提供 GitHub 链接),但核心逻辑如下:
1 | // 读取流式响应 |
效果如下:
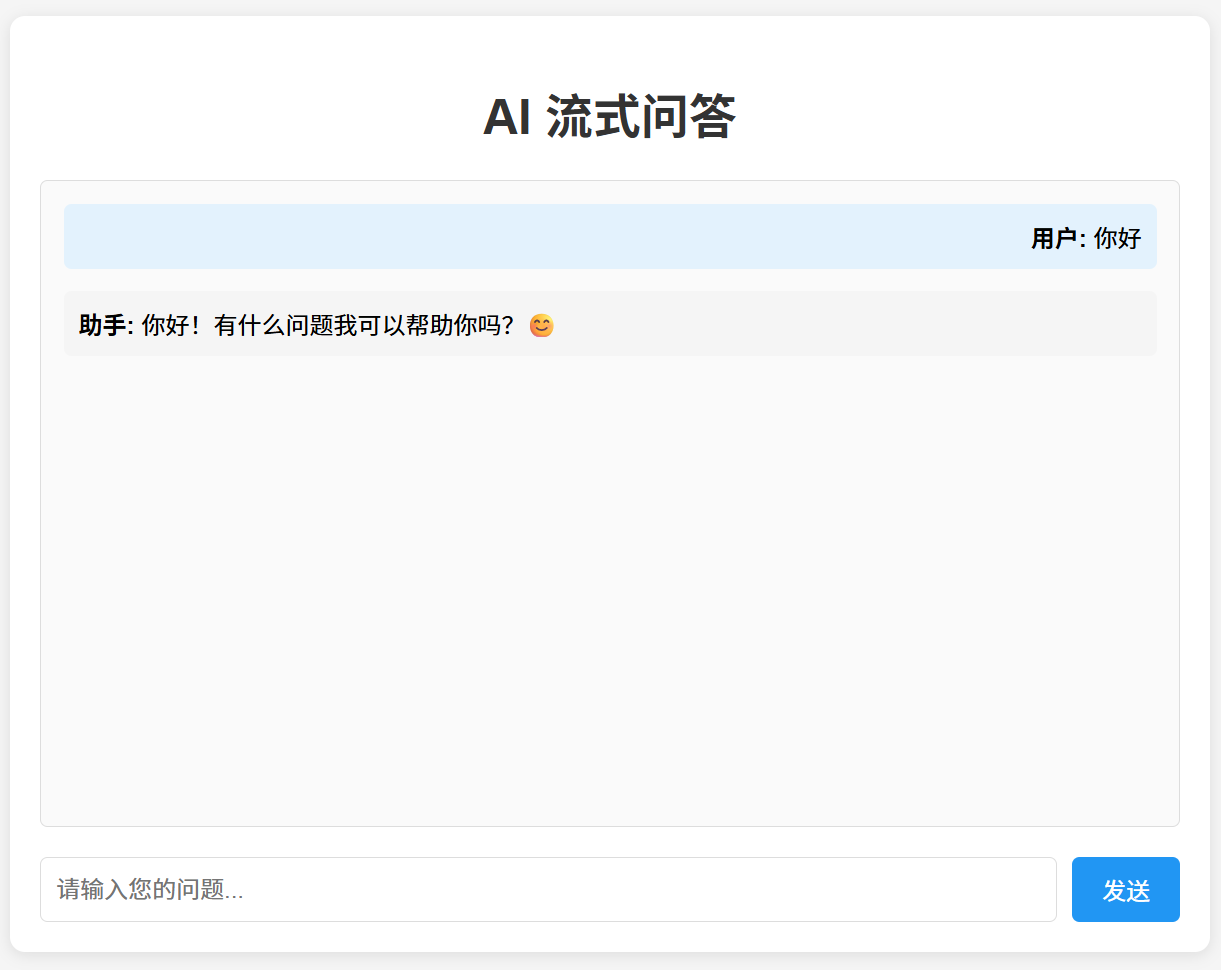
(实际运行效果:用户提问后,AI 文字逐字“打出来”)
▶️ 如何运行?
安装依赖:
1
pip install fastapi openai python-dotenv uvicorn
启动后端:
1
python main.py
打开
index.html(建议用 Live Server 插件或本地 HTTP 服务)
⚠️ 注意:由于浏览器安全策略,直接双击打开
index.html可能无法跨域请求localhost:8000。推荐用 VS Code 的 Live Server 或 Python 快速启动:
然后访问
http://localhost:8080/index.html
🌐 扩展建议
- 生产部署:用 Docker Compose 将 FastAPI 和前端打包,配合 Nginx 反向代理。
- 多轮对话:前端保存
messages历史,每次请求带上完整上下文。 - Token 统计:利用
stream_options={"include_usage": True}获取消耗详情。 - 换模型:DashScope 还支持
qwen-max、qwen-turbo,按需切换。
🎁 结语 & 源码
通过这个小项目,你不仅掌握了 流式 AI 响应 的实现方式,还学会了如何对接阿里云的大模型服务。FastAPI 的简洁与强大,加上前端的轻量交互,让 AI 应用开发变得前所未有的简单!
🔗 完整代码已开源:
GitHub 地址:https://github.com/guopingd/fastapi_learn/tree/main/fastapi-qwen-stream-chat